Precision at Scale: Domain-Specific Datasets On-Demand
Abstract
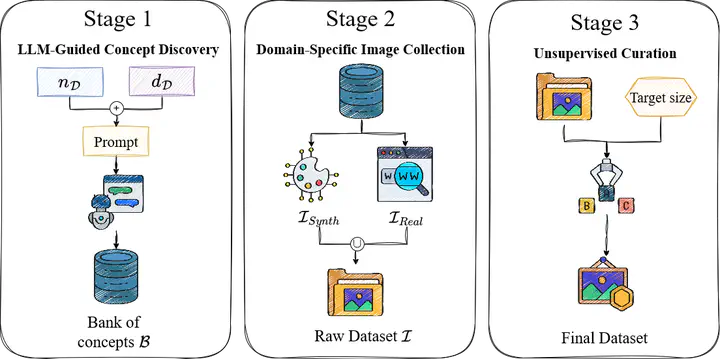
Recent self-supervised learning methods rely on massive general-domain datasets for robust model pretraining. However, these datasets may lack specificity required in specialized domains. Collecting large, supervised datasets to compensate for this limitation is also cumbersome. This raises a key question: Can automatically crafted domain-specific datasets serve as efficient and effective SSL pretrainers, performing comparable to—or even surpassing—much larger state-of-the-art general-domain datasets? To address this challenge, we propose Precision at Scale (PaS), a novel modular pipeline for automatic creation of domain-specific datasets on-demand. PaS leverages Large Language Models (LLMs) and Vision-Language Models (VLMs) through three distinct phases: Concept Generation, where LLMs identify relevant domain concepts; Image Collection, utilizing VLMs and Generative models to gather appropriate images; Data Curation, ensuring quality and relevance by eliminating unrelated or redundant images. We conduct extensive experiments across three complex domains — food, insects, and birds — proving that PaS datasets compete and often surpass existing domain-specific datasets in diversity, scale, and effectiveness as pretrainers. Models pretrained on PaS datasets outperform those trained on large-scale general-domain datasets (ImageNet-1K) by up to 21% and surpass same-scale domain-specific datasets by 6.7% across classification tasks. Notably, despite being an order of magnitude smaller, PaS datasets outperform ImageNet-21K pretraining, with improvements of 3.3 % in fine-tuning and 9.5% in few-shot learning, and showing superior performance on specialized dense tasks. Furthermore, by efficiently fine-tuning pretrained VLMs like CLIP and SigLIP using low-rank methods, we achieve performance gains (+4.2 % over CLIP) in specialized domains with minimal overhead, demonstrating the versatility of PaS datasets.
Jesús M. Rodríguez-de-Vera
PhD Candidate in Computer Vision
My research interests include computer vision, deep learning and artificial intelligence.